Vortrag zum Thema Deanonymisierung – VDI Zollern-Baar
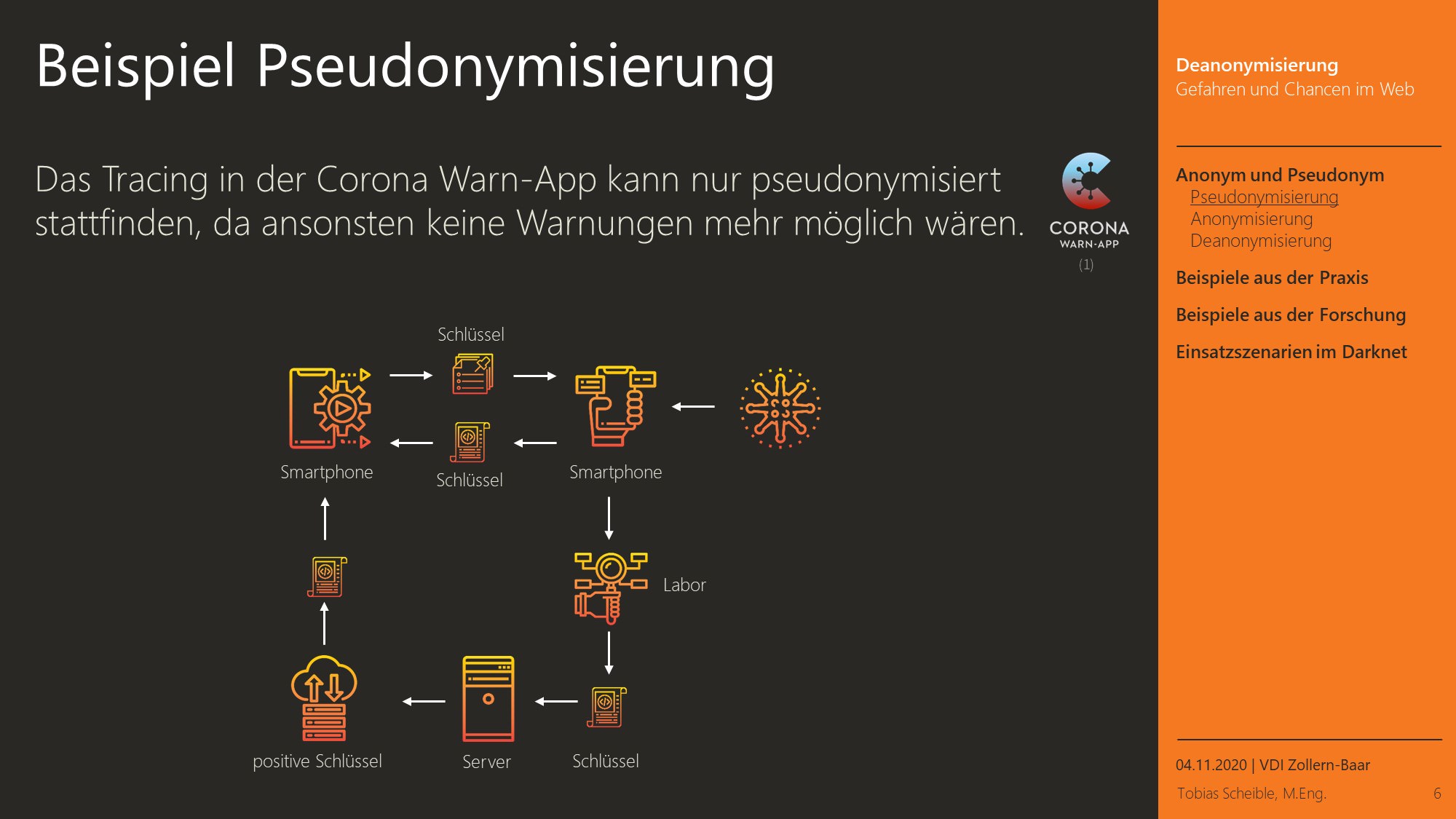
Üblicherweise werden personenbezogene Daten aufgrund der Anforderungen des Datenschutzes pseudonymisiert oder anonymisiert. Dadurch können sie von anderen Abteilungen, externen Drittunternehmen oder Forschungseinrichtungen weiterverarbeitet werden.
Anhand von Beispielen aus der Forschung zeigte ich, wie vermeintlich anonymisierte Daten durch die Kombination aus verschiedenen Quellen wieder aggregiert und somit deanonymisiert werden können. Aufgezeigt wurde außerdem, welche Möglichkeiten zur Deanonymisierung in Tor-Netzwerken im Darknet in der Forschung diskutiert und welche Methoden vermeintlich von Ermittlungsbehörden eingesetzt werden.
Anonym und Pseudonym
Um personenbezogene Daten weiter verarbeiten zu können, werden Daten zur Feststellung der Identität unkenntlich gemacht – entweder durch Pseudonymisierung oder Anonymisierung. Der Versuch, diese Daten wieder einer bestimmten Person zuzuordnen, wird Deanonymisierung genannt.
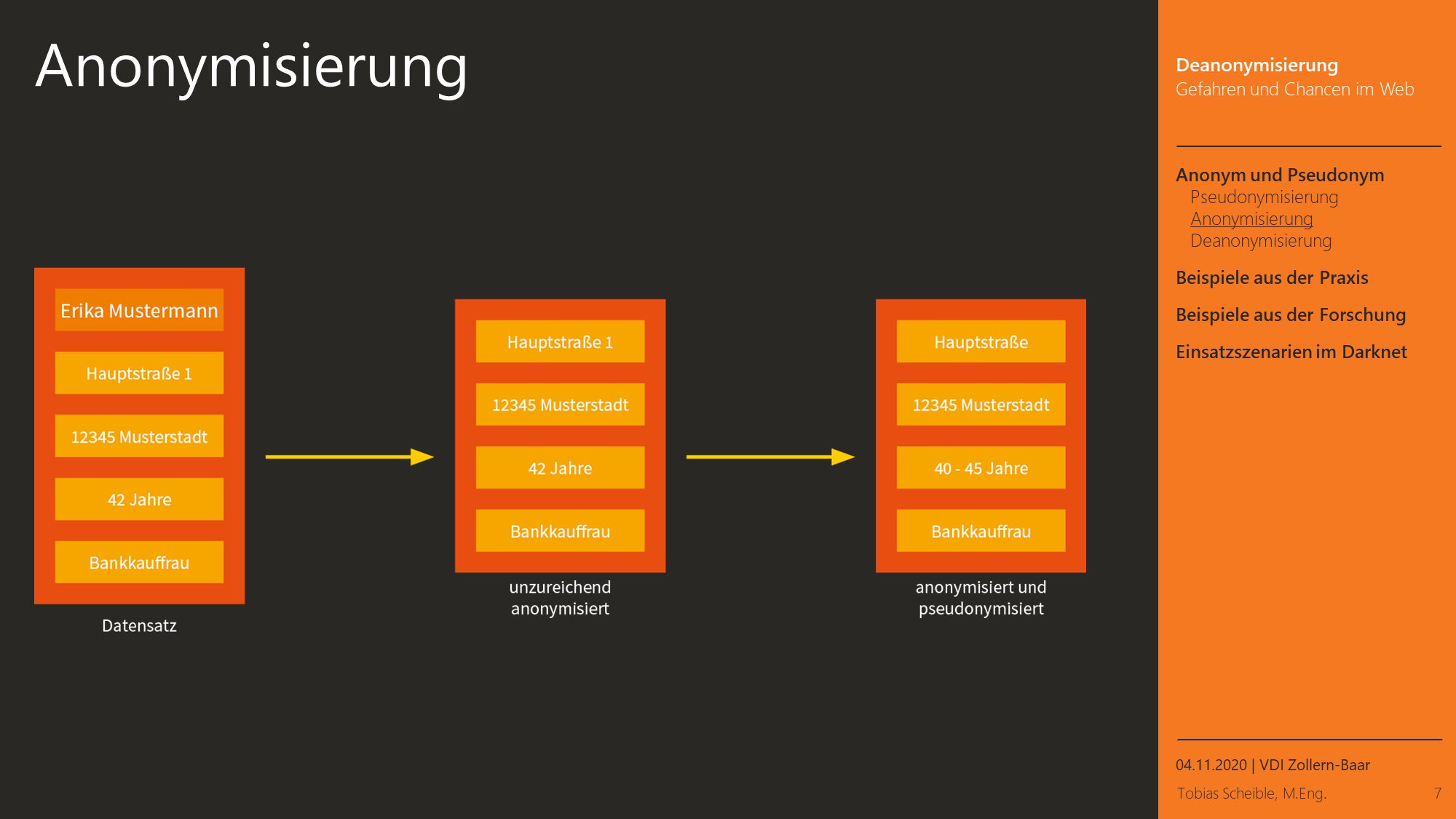
Bei der Pseudonymisierung werden eindeutige Merkmale zur Identifikation wie Benutzernamen, E-Mail-Adresse oder der realen Namen durch ein Pseudonym ersetzt. Dieses Pseudonym besteht meist aus einer Kombination aus Buchstaben und Zahlen, entweder gleichmäßig verteilt oder zufällig gewählt. Wichtig sind bei der Pseudonymisierung neben eindeutigen Merkmalen wie beispielsweise dem Namen auch alle anderen Daten, die eine einfache Identitätsfeststellung ermöglichen, wie zum Beispiel die Anschrift. Entweder müssen diese Merkmale entfernt oder in Gruppen zusammenfasst werden, die zu unscharf für eine Zuordnung sind.
Im Gegensatz zur Pseudonymisierung werden bei der Anonymisierung die identifizierten Merkmale komplett entfernt, so dass auch später keine Zuordnung mehr durchgeführt werden kann. Auch hierbei gilt, dass alle potentiellen Identifikatoren entfernt werden müssen oder durch Pseudonymisierung in allgemeine Gruppen überführt werden müssen. Die komplette Entfernung aller Merkmale wird auch als „rücknahmefest“ bezeichnet.
Erfolgt eine unzureichende Pseudonymisierung bzw. Anonymisierung, können diese Daten mit einer anderen Datenquelle kombiniert werden und so kann eine eindeutige Zuordnung wiederhergestellt werden. Hierbei wird auch von k-Anonymität gesprochen. Aber nicht nur Daten, die anonymisiert wurden, können von einer Deanonymisierung betroffen sein. Sondern auch Daten, die vermeintlich keiner Person zugeordnet sind, können durch Kombinationen mit mehreren Datenbanken am Ende wieder einer Person zugeordnet werden. Dadurch können auch Datensätze relevant sein, die auf den ersten Blick problemlos veröffentlicht werden können.
Beispiele aus der Praxis
In der Praxis gibt es immer wieder Vorfälle mit fehlerhafter Pseudonymisierung oder Anonymisierung, die schlussendlich zu einer Deanonymisierung führen.
In einem Unternehmen hatte sich eine Person mit einer ansteckenden Krankheit infiziert. Die Personalabteilung hat daraufhin alle Mitarbeiter der betroffenen Abteilung informiert, damit diese entsprechenden Maßnahmen treffen und auf Anzeichen der Krankheit achten können. Natürlich wurde nicht direkt kommuniziert, welche Person sich mit welcher Krankheit infiziert hat. In der Mail an die Mitarbeiter mit einem offenen Verteiler wurde aber die erkrankte Person ausgenommen. Wodurch alle Mitarbeiter wussten, wer die betroffene Person ist.
Um im Web eine Person bzw. dessen Webbrowser eindeutig zu identifizieren wird die Technik des Webbrowser Fingerprinting eingesetzt. Dabei werden nicht die IP-Adresse oder Cookies für das Tracking verwendet, sondern die Summe aus möglichst vielen Merkmalen. Es wird zum Beispiel die Version des Browsers, die installierten Schriften, die eingesetzte Auflösung und sogar die Grafikkarte ausgelesen. Mit diesen Informationen wird mit einem Algorithmus ein Fingerabdruck erstellt. Damit ist der Webbrowser ohne gespeicherte Informationen auf dem Client immer wieder von verschiedenen Servern und Anbietern identifizierbar. Dies kann selbst mit dem Dienst amiunique.org getestet werden.
Anonym im Internet surfen, damit werben VPN-Anbieter. Allerdings wird bei einer VPN-Verbindung nur eine verschlüsselte Verbindung zum Server des Anbieters aufgebaut. Der Anbieter hat vollen Zugriff auf den Netzwerkverkehr und nur die IP-Adresse wird damit verschleiert. Sobald ein Login erfolgt oder die oben beschriebene Variante durchgeführt wird, kann eine Zuordnung erfolgen.
Beispiele aus der Forschung
Verschiedene Forscherinnen und Forscher beschäftigen sich mit der Frage, wie verschiedene Daten korreliert werden können, um eine eindeutige Zuordnung zu erzielen. Darunter gibt es einige Projekte, die beispielhaft aufzeigen, wie eine Deanonymisierung durchgeführt werden kann. Dies gibt einen Einblick, welche Techniken zur Aufhebung der Anonymisierung möglich sind, und welche Szenarien bereits stattgefunden haben.
Netflix veröffentlichte seine Datenbank mit 100.480.507 Datensätzen in anonymisierter Form im Rahmen eines Wettbewerbs mit dem Ziel, die Empfehlungsservices zu verbessern. Es wurden alle Daten entfernt, die einen personenbezogenen Bezug erlauben könnten. Daraufhin nutzten Forscher diese Datensätze, um zu untersuchen, ob dennoch eine Deanonymisierung möglich ist. Da die Datensätze von Netflix hauptsächlich Konten mit mehreren Bewertungen von Filmen beinhalteten, wurden diese mit den Bewertungen aus der Internet Movie Database (IMDb) abgeglichen. Hierbei wurde versucht, zwischen diesen beiden Datenbanken Korrelationen zu entdecken, die auf Bewertungen für gleiche Filme in den beiden Datenbanken innerhalb eines ähnlichen Zeitraums basierten. Mit nur acht Bewertungen, von denen sogar zwei falsch sein dürfen, und Bewertungszeiträumen, die bis zu 14 Tage auseinanderliegen, konnten 99% der Datensätze eindeutig zugeordnet werden.
Chris Whong hat eine Datenbank der Taxifahrten in New York ausgewertet. Die Daten erhielt Whong als rund 20 GB große Datei im CSV-Format mit ca. 170 Millionen Einträgen zu Taxifahrten. Neben Datum, Uhrzeit und GPS-Koordinaten von Start und Ziel der Fahrten, befanden sich außerdem die anonymisierten Werte für das Nummernschild und die Lizenznummer im Datensatz. Die Daten wurden vor der Herausgabe mit einem MD5 Hash-Algorithmus pseudonymisiert. Die Nummernschilder der Taxis in New York sind nach einem bestimmten Schema aufgebaut und diese Informationen sind frei verfügbar. Daraus ergibt sich, dass nur ca. zwei Millionen Varianten möglich sind. Zusätzlich sind die Lizenznummern ebenfalls nach einer definierten Struktur organisiert, wobei hier etwa 22 Millionen Möglichkeiten existieren. Werden alle berechneten Nummernschilder und Lizenznummern kombiniert, erhält man eine Liste aller Möglichkeiten. Mit diesen vorberechneten Daten ist es dann ein Leichtes, alle MD5-Hashes zu berechnen und einen Abgleich mit den zur Verfügung gestellten Datensätzen durchzuführen.
Forscher haben in einer Studie (Nature) untersucht, wie viele Merkmale benötigt werden, um einen US-Bürger eindeutig zu identifizieren. Als Ausgangmaterial wurden verschiedene frei zugängliche Datenbanken genutzt. Dabei wurden sämtliche direkt identifizierenden Daten wie der Name, die Adresse oder die E-Mail entfernt. Mit der Methode der Untersuchung konnten 83% der US-Bürger klar identifiziert werden, selbst wenn nur Geschlecht, Postleitzahl und Geburtstag bekannt sind. Sobald 15 Merkmale einbezogen wurde, lag die Quote bei 99,98%.
Weitere Beispiele habe ich in meinem Blog-Artikel „Deanonymisierung – Beispiele aus der Forschung“ beschrieben.
Einsatzszenarien im Darknet
Das Darknet im Tor-Netzwerk polarisiert und steht häufig im Fokus der medialen Berichterstattung über Cyberkriminelle. Mit diesem speziellen Netzwerk kann eine anonymere Nutzung des Internets erfolgen, allerdings existieren auch hier verschiedene Möglichkeiten zur Deanonymisierung. Besonders Ermittlungsbehörden haben hier häufig großes Interesse, Maßnahmen zur Deanonymisierung durchzuführen.
Das Tor-Netzwerk basiert auf dem Prinzip, dass eine Kommunikation nicht wie sonst üblich direkt, sondern über mehrere Stationen (auch Knoten – engl. notes – genannt) erfolgt. In der Standardkonfiguration sind dies drei Stationen. Dabei wird mit jeder Station ein individueller Schlüssel für die Verschlüsselung ausgehandelt und die Daten werden mehrmals verschlüsselt, daher wird auch von Schichten gesprochen. Jede Station kann nur die jeweilige eigene Schicht entschlüsseln und erhält damit die Informationen, welches die nächste Station ist. Dadurch kann keine der übermittelnden Stationen auf die eigentlichen Daten zugreifen und jede Station kennt in der Kommunikationskette immer nur die Stationen davor und dahinter.
Der Netzwerkverkehr wird zwar über mehrere Stationen jeweils separat verschlüsselt übertragen, muss aber am Ende wieder eine Verbindung in das „normale“ Internet aufnehmen. Dies geschieht über sogenannte Exit-Nodes. Sie stellen das Ende der verschlüsselten Kommunikationskette dar und stehen dadurch im Visier von Überwachungsaktionen. Da das Tor-Netz von Freiwilligen betrieben wird, kann jede Person oder Institution weitere Stationen bzw. Knoten dem Tor-Netzwerk hinzufügen. Dies gilt auch für Exit-Nodes. Daher muss sich nicht die Mühe gemacht werden, Exit-Nodes zu infiltrieren, sondern kann stattdessen eigene betreiben.
Ist eine großflächige Analyse des Netzwerkverkehrs im Internet möglich, können Nutzer auch trotz der Verschlüsselung mit statistischen Analysen identifiziert werden, ohne Exit-Nodes zu kontrollieren. Um dies zu erreichen, wird der Traffic eines Anschlusses untersucht und hinsichtlich zeitlicher Abfolgen und Anzahl der Datenpakete analysiert. Dann wird versucht, im gesamten Internettraffic ähnliche Datenströme zu finden und so die Zwischenstationen bzw. das Ziel zu identifizieren. Da bekannt ist, welche Veränderungen an Datenpaketen mit dem Transfer durch das Tor-Netzwerk vorgenommen werden, kann diese Veränderung bei der Analyse herausgerechnet werden. Die Methode ist natürlich sehr aufwendig und benötigt enorme Ressourcen, wie sie wahrscheinlich Geheimdiensten zur Verfügung stehen.
Eine weitere Methode ist die Ausnutzung von Schwachstellen im Web-Browser der Tor-Netzwerknutzer. Hier werden entweder alte Systeme über bekannte Sicherheitslücken angegriffen oder sogenannte Zero-Days Exloits eingesetzt, also Sicherheitslücken ausgenutzt, die den Herstellern nicht bekannt sind und für die es keine Sicherheitspatches gibt.
Grundsätzlich sollte immer die aktuellste Version des Tor Browsers verwendet werden und nur wenige Plugins installiert werden. Als zusätzliche Maßnahme können Entry und Exit Nodes nur aus bestimmten Ländern verwendet werden. Alternativ können vertrauenswürdige Exit Nodes fest konfiguriert werden. Diese Maßnahmen sollten aber nur durchgeführt werden, wenn die Auswirkungen bekannt sind. Eine fehlerhafte Konfiguration kann zum Gegenteil führen.
Online-Vortrag
Der Online-Vortrag „Gefahren und Chancen der Deanonymisierung im Web“ fand im Rahmen des VDI Zollern-Baar Programms am 4. November 2020 ab 19:15 Uhr statt. Die kompletten Folien des Vortrags gibt es als Download (PDF) und können hier direkt angeschaut werden: